Mechanistic Interpretability Beyond Language Models
Table of Contents
Abstract
In the recent times, a plethora of mechanistic interpretability methods have been developed, used towards understanding, modifying and steering different aspects of language models. However, progress towards mechanistically understanding multimodal and vision models have been slow when compared to the interest in mechanistic interpretability for language models.
In the past one year, Reliable AI Lab at UMD has been developing and adapting interpretability tools to understand the inner workings of multimodal and vision models, with a downstream emphasis on applications such as
- Removing copyrighted content in T2I models without fine-tuning
- Improving compositionality with interpretability insights
- Mitigating spurious correlations in vision models in a zero-shot manner
- Updating rare knowledge in MLLMs via model editing
While we recognize the importance and critical role of downstream applications in validating interpretability research, our primary focus has been to uncover novel and insightful understandings of the inner workings of foundational vision and vision-language models. We believe that a mechanistic understanding of these models will lead to targeted interventions to make them reliable in the long run.
In terms of applications, we find that the methods we develop using interpretability insights are in-fact at par with specialized methods but with the advantage of being light-weight. For e.g., for text-to-image generative models, we find that editing just a small set of layers (or even a single layer for early Stable-Diffusion variants) can prevent the generation of copyrighted content (e.g., artistic style) in just a second. In a similar line, we find that compositionality in text-to-image models can be improved by solely learning a linear map on the conditioning mechanism. For vision models, we find that there exists scope for mitigating spurious correlation without the need of fine-tuning (though more work is warranted in this nascent area).
Our blog provides a comprehensive overview and summary of our year-long efforts in mechanistic interpretability in foundational models beyond language models and discusses the open research problems in this area.
Causal Layers in UNet and Text-Encoder of Text-to-Image Diffusion Models
In language models, prior work has shown that factual knowledge can be effectively localized to a small set of layers. These layers are localized via causal interventions which measure the change in model outputs by perturbing an internal layer. In this project, we adapt causal interventions to text-to-image diffusion models to understand if knowledge about various visual attributes can be localized to a small number of layers. The purpose of mechanistically understanding generative models is two-fold:
- A mechanistic understanding of generative models about how they represent knowledge can uncover novel scientific understanding about their inner workings.
- Understanding the inner workings of diffusion models can help us design effective unlearning strategies towards preventing the model towards generating copyrighted content (e.g., certain artistic styles).
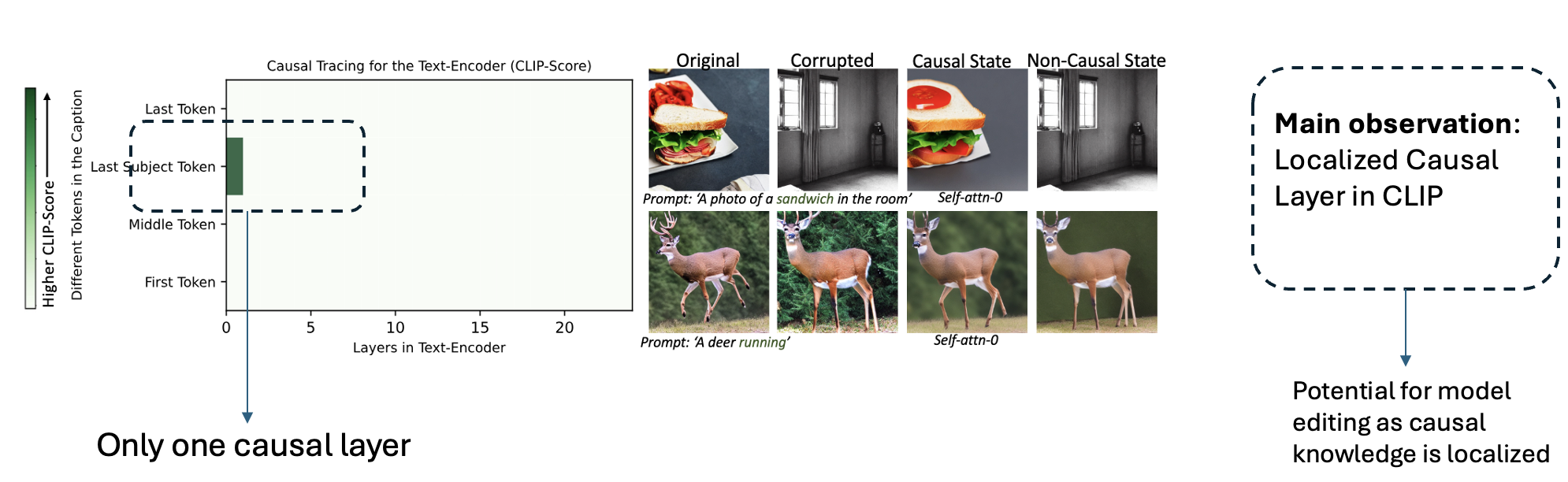
We apply causal interventions in the UNet (noise-prediction module) of the diffusion model as well as the text-encoder. In the UNet, we find that knowledge about different visual attributes is distributed. However, we find that this distribution across layers is highly dependent on the visual attribute. For example, knowledge about style is distributed differently than knowledge about action in the images.

In the text-encoder, we surprisingly find only one causal state which can control the output of generative models. In particular this is the first self-attention layer. As shown below, we find that this layer can control various visual attributes such as copyrighted styles, objects and general factual knowledge.
Using these interpretability insights, we then develop DiffQuickFix — a fast and effective model editing algorithm to prevent diffusion models from generating copyrighted content. The idea of DiffQuickFix is simple: update the projection layer in the causal first self-attention layer in the CLIP text-encoder such to create new associations between certain keys (e.g., Van Gogh style) and values (e.g., painting). In essence, post-editing the text-encoder, the model will always map a ‘Van Gogh’ style to a generic painting which will ensure that the diffusion model is not able to generate the copyrighted content. Finally, we note that DiffQuickFix is extremely fast and it can edit concepts in under 1 seconds, almost a 1000x speedup over various fine-tuning based unlearning methods.
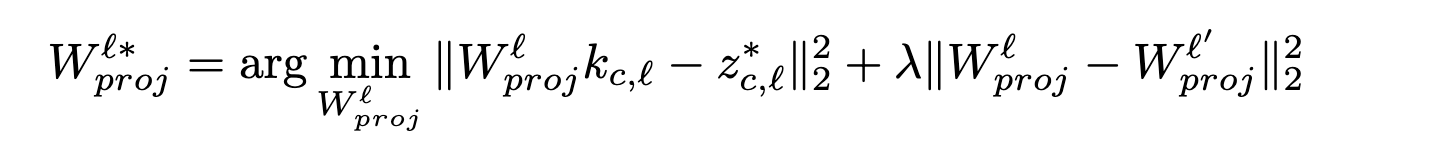
Below we show examples of our model editing algorithm:

The primary limitation of our method is that it is dependent on diffusion models which utilize a single CLIP text-encoder in the pipeline. In the next section, we provide a more universal framework towards knowledge localization and editing across various open-source text-to-image models.
📚 Paper: “Localizing and Editing Knowledge in Text-to-Image Generative Models” ICLR 2024
🌐 Webpage: Explore!
Localizing Knowledge in Cross-Attention Layers
Given the limitations of causal tracing for localizing knowledge within text-encoders of recent models, we sought to develop a more generalizable approach for knowledge localization in text-to-image models—one that could be effectively scaled and applied to modern architectures. In this work, we investiage whether knowledge representing artistic styles, objects, or facts can be localized in cross-attention layers of text-to-image models. Interestingly, we observed that among significant number of cross attention layers, only a select few play a key role in controlling the generation of specific concepts. In fact, the model heavily relies on information provided by those layers to generate those concepts. e.g., we observed that in Stable Diffusion XL, layers 45-48 among 64 layers are responsible for Van Gogh style. Modifying the input only in these specific layers leads the UNet to produce an image that noticeably loses its Van Gogh characteristics.

Localization within few layers enables an efficient and surgical model editiing method that aims to minimally modify cross-attention layers in those specified layers. This happens by carefully editing key value matrices within those layers, mapping original text prompts to representations that exclude the targeted concept. More specifically, we solve the following optimization problem for key and value matrices of localized cross-attention layers:
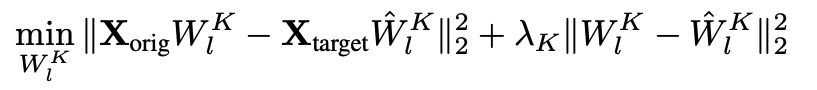
Above optimization problem has a closed-form solution, enabling us to effeciently edit the model.

Importantly, the edited models retain their general utility and continue to generate high-quality images when prompted with general inputs. The localization approach worked for SD-v1.4, SD-v2, SD-XL, DeepFloyd and OpenJourney. However, model editing in DeepFloyd results in erroneous edits. This has potentially to do with the bi-directional attention in T5, which leads to leakage of information in other tokens more than causal attention in models such as CLIP.
📚 Paper: “On Mechanistic Knowledge Localization in Text-to-Image Generative Models” ICML 2024
🌐 Webpage: Explore!
Future Directions
This work opens up various research questions such as:
- What is the best way to edit text-to-image models with T5 text-encoder?
- Recent models often utilize DiT as their generative backbone, raising important questions about knowledge localization within these architectures. Specifically, do they exhibit similar localization behaviors as earlier UNet-based models?
Compositionality in Diffusion Models
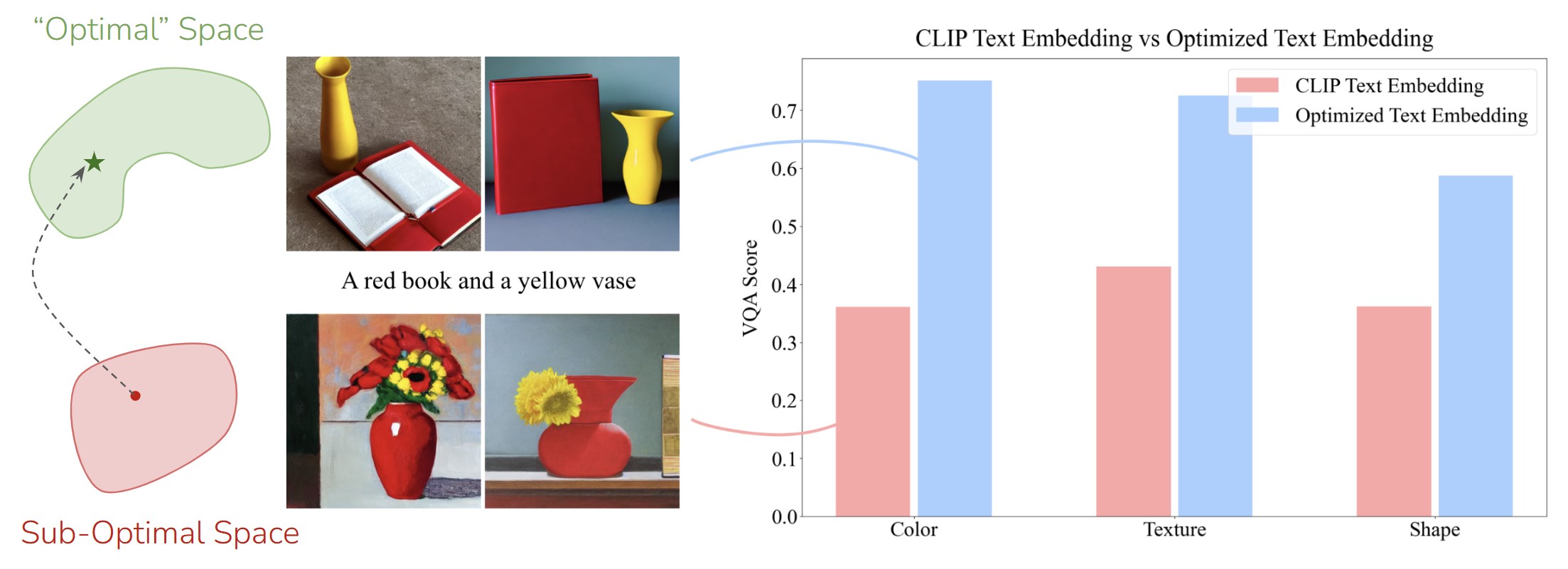
Text-to-image generative models, especially diffusion-based ones like Stable Diffusion, have revolutionized how we create visual content. However, they often struggle with one critical aspect: compositionality. This refers to their ability to accurately combine attributes, objects, and their relationships into a coherent image. For instance, prompts like “a red book and a yellow vase” often result in images where the attributes are swapped, misaligned, or an object is missing (e.g. images representing “a red book and a red vase” or “a red book”).
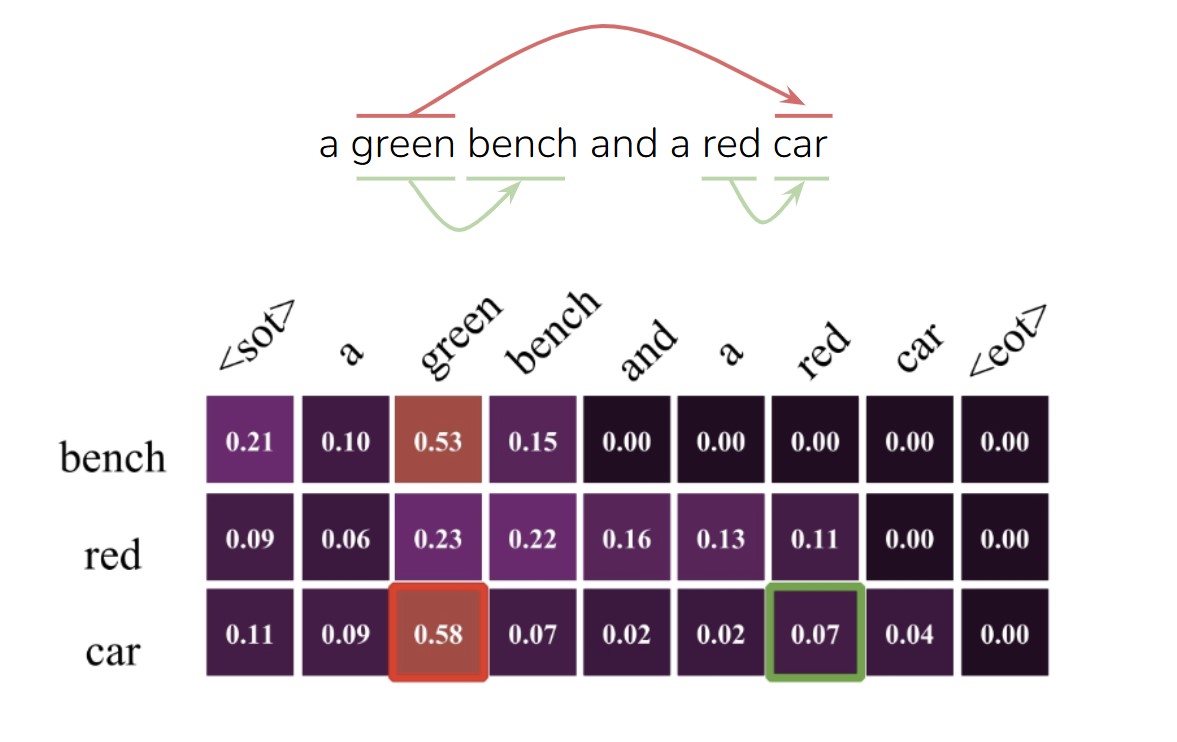
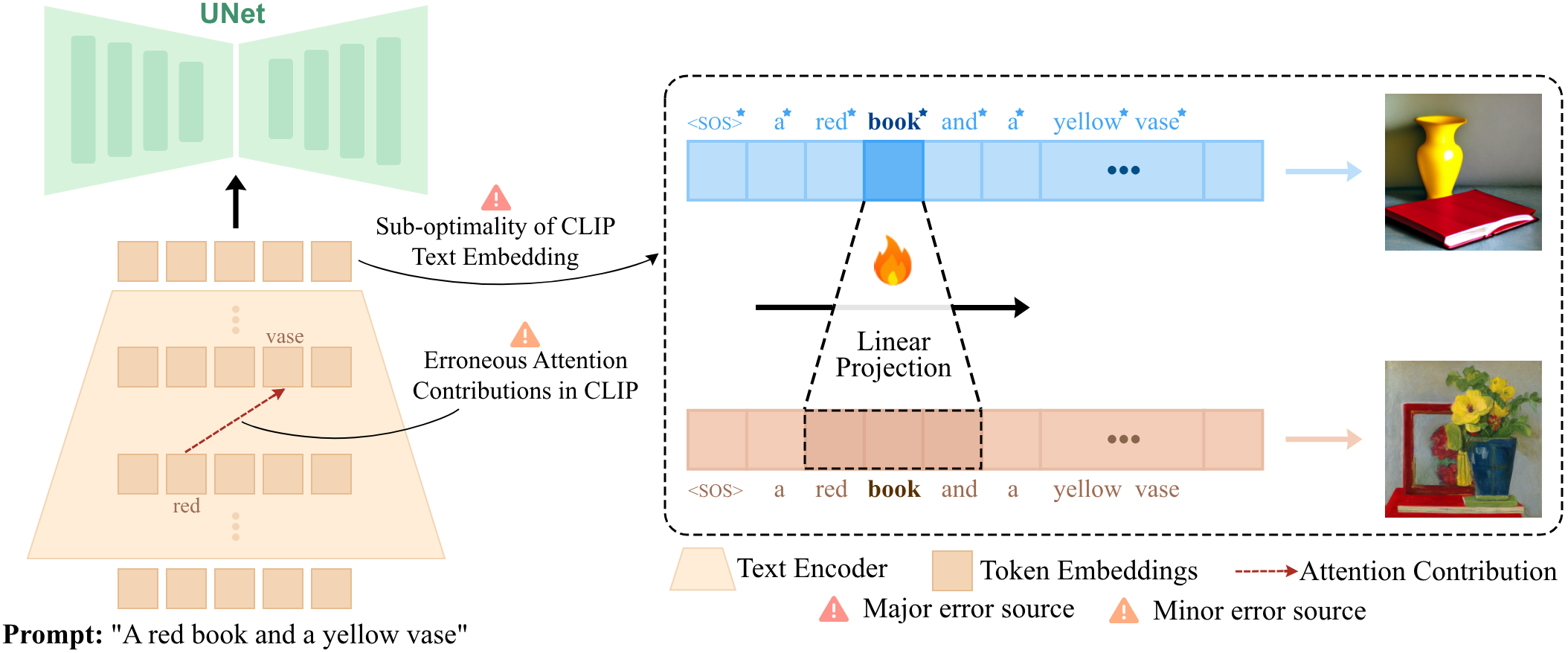
To tackle this challenge, we first sought to thoroughly understand and analyze the root of compositionality failures. As an initial step, we delved into the attention contributions within the CLIP text-encoder for each token. This analysis revealed a significant insight: the CLIP text-encoder, which is widely used in text-to-image generative models, frequently generates embeddings with irrelevant attention contributions.
For instance, in a prompt like “a green bench and a red car”, the token “car” should primarily attend to “red” to correctly bind the attribute to the object. However, as can be seen from the image below, our analysis shows that “car” often erroneously attends to “green”, leading to attribute-object mismatches in the generated images.
Next, we analyze the embedding space of the CLIP text-encoder, which serves as input to the UNet in Stable Diffusion. Our goal is to demonstrate that the text embeddings generated by CLIP are suboptimal for creating compositional scenes. Importantly, we show that a more optimal embedding space exists, which can significantly enhance compositionality.
To achieve this, we take the following approach: for each compositional prompt, we extract the embedding tokens generated by CLIP (producing a 77xd tensor). We then make this tensor learnable, effectively treating it as a trainable parameter. Keeping the UNet frozen, we optimize this embedding tensor using valid compositional prompt-caption pairs and using diffusion loss. By iterating this process across all prompts, we observe a notable improvement in the model’s compositional performance when the optimized embeddings are passed to the UNet.
This finding underscores that the CLIP text-encoder’s current output space is a significant bottleneck, and aligning it with a more optimal space could greatly enhance compositionality. (Refer to the figure below for a visual demonstration)
Building on our earlier analysis, we introduce WiCLP (Window-based Compositional Linear Projection), a lightweight method to enhance text embeddings by applying a linear projection over a token’s context window.
To train WiCLP, we first gather a set of high-quality compositional prompt-image pairs. Keeping both the CLIP text-encoder and the UNet frozen, we train a linear projection layer on top of CLIP’s output embedding space, optimizing it using the diffusion loss. This approach ensures that the projection effectively maps the suboptimal CLIP embeddings to a more suitable space for compositional image generation. The image below provides a comprehensive overview of our framework, analysis, and proposed method.
Our results demonstrate that this simple yet efficient projection method significantly improves the compositionality of text-to-image models, outperforming many state-of-the-art approaches that rely on much more complex and resource-intensive optimizations.
The images below illustrate how our proposed method enhances the cross-attention masks within the UNet and also leading to a significant improvement in the model’s overall compositional performance.


📚 Paper: “Understanding and Mitigating Compositional Issues in Text-to-Image Generative Models”
🌐 Webpage: Explore!
Future Directions
This work opens up various research questions such as:
- Expanding to Other Types of Compositionality: How can our analysis and methods be extended to improve other aspects of compositionality, such as spatial relationships or numerical reasoning?
- Handling Complex Prompts: Can our approach be adapted for compositional prompts with longer text sequences, where the distance between adjectives and their corresponding nouns is greater?
- Improving CLIP for Compositionality: Is it possible to refine CLIP itself to inherently improve its compositional performance? A better-trained CLIP text-encoder could serve as a stronger foundation for generative models like Stable Diffusion.
Mechanistically Understand Model Components Across Different ViTs
In text-to-image models, we were able to analyze and control the generation of concepts via causal tracing by perturbing carefully chosen text tokens in the input which correspond to the concept of interest. However, in vision models with image inputs, it is more challenging to carefully control and perturb the chosen concepts, which means that causal tracing is less effective in this setting. Thus, rather than understanding the model from the input side, we aim to understand the model from the representation side. Specifically, we use the following approach:
- We decompose the final representation as a sum of contributions from different model components. Furthermore, each of these component contributions can be decomposed over the image patch tokens.
- We then map each of these contributions to CLIP space where they can be interpreted using CLIP’s shared image-text representation space
- Using the CLIP text-encoder, we identify which components are responsible for encoding which concepts, and manipulate them to perform some downstream task
We validate our findings by applying them on tasks like:
-
Token importance visualization: Each component contributioncan be further broken down into token-wise contributions. This can be used to visualize the importance of each token in the final representation with respect to a given property and/or component.
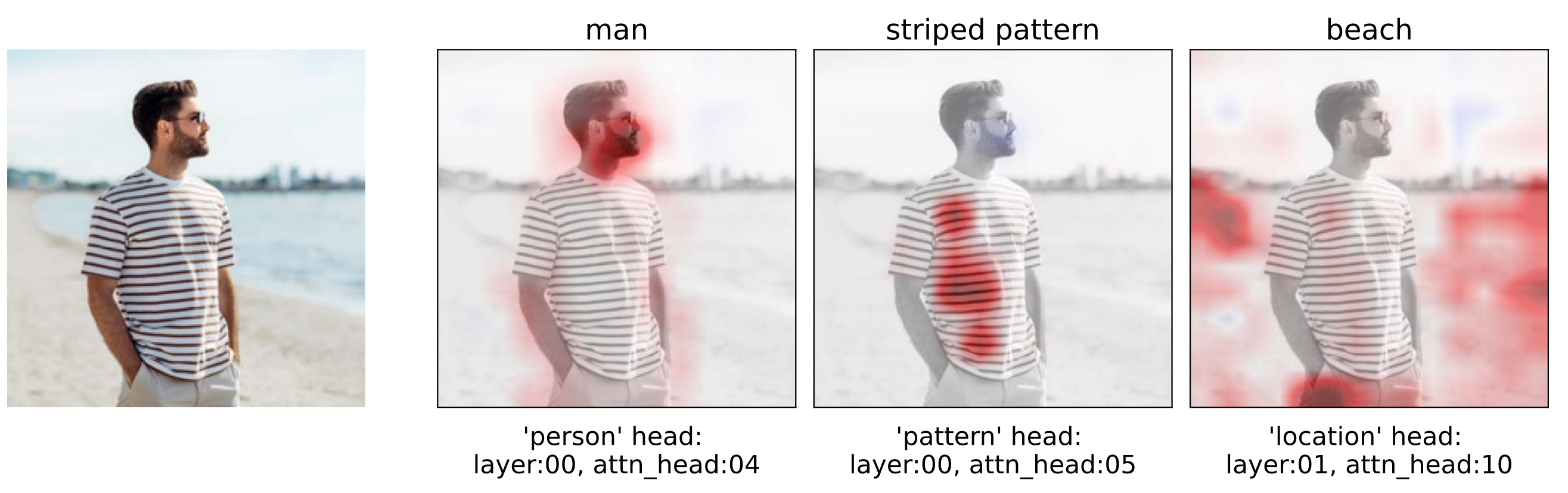
Fig. 13: Visualization of token contributions as heatmaps. The relevant feature and the head most closely associated with the feature is displayed on the bottom of the heatmap, while the feature instantiation is displayed on the top. -
Image-based image retrieval: Model components which are responsible for encoding a particular property can be used to retrieve images which are close to a given probe image with respect to that property!

Fig. 14: Top-3 images retrieved by the most significant components for various features relevant to the reference image (on the left). -
Mitigating unwanted spurious correlations: By ablating the top 10 model component contributions associated with ‘location’ (but not with ‘bird’!), we are able to achieve an increase in the worst group accuracies for a variety of transformer based models
Model name Worst group accuracy Average group accuracy DeiT 0.733 → 0.815 0.874 → 0.913 CLIP 0.507 → 0.744 0.727 → 0.790 DINO 0.800 → 0.911 0.900 → 0.934 DINOv2 0.967 → 0.978 0.983 → 0.986 SWIN 0.834 → 0.871 0.927 → 0.944 MaxVit 0.777 → 0.814 0.875 → 0.887
For more details, please checkout the links below:
📚 Paper: “Decomposing and Interpreting Image Representations via Text in ViTs Beyond CLIP” NeurIPS 2024
🌐 Webpage: Explore!
Future Directions
Although we were able to localize certain concepts via this approach, there are still many open questions. For one, we found that the direct controbutions of model components are not limited to one role - they are responsible for jointly encoding many concepts along with other concepts. This makes it difficult to ablate them without affecting other concepts. One way to address this is to probably select a subspace within each component that is responsible for encoding a single concept. Another direction is to understand how these components interact with each other to encode concepts, as it is likely that concept components are built out of simpler ones.
Understanding Internal Components in Multimodal Language Models
So far, we have adapted mechanistic interpretability methods for understanding text-to-image models and vision transformers. With the interest of the community of Multimodal Language Models for various tasks such as VQA, recaptioning datasets for training foundational models better — we design and adapt methods to understand the inner workings of Multimodal Language Models such as LLava and Phi-vision. In this project, we investigate how Multimodal Language models process information for a representative VQA task. To this end, we first curate a dataset which is annotated with “constraints”. For example, given an image of a Space Needle and a question, “Where is this building located in”? — the tokens corresponding to “this building” are constraints. We curate a dataset called VQA-Constraints consisting of 9.7k questions (with their respective image) and annotate them with constraints. With this richly annotated dataset, we answer the following questions:
- How does the language part of the MLLM retrieve information corresponding to the constraints I.e., what are the causal layers for VQA task with a visual prompt?
- How does the visual information flow to the causal layers (or token positions) corresponding to the constraints?
- Can we edit MLLMs to incorporate rare knowledge into them?
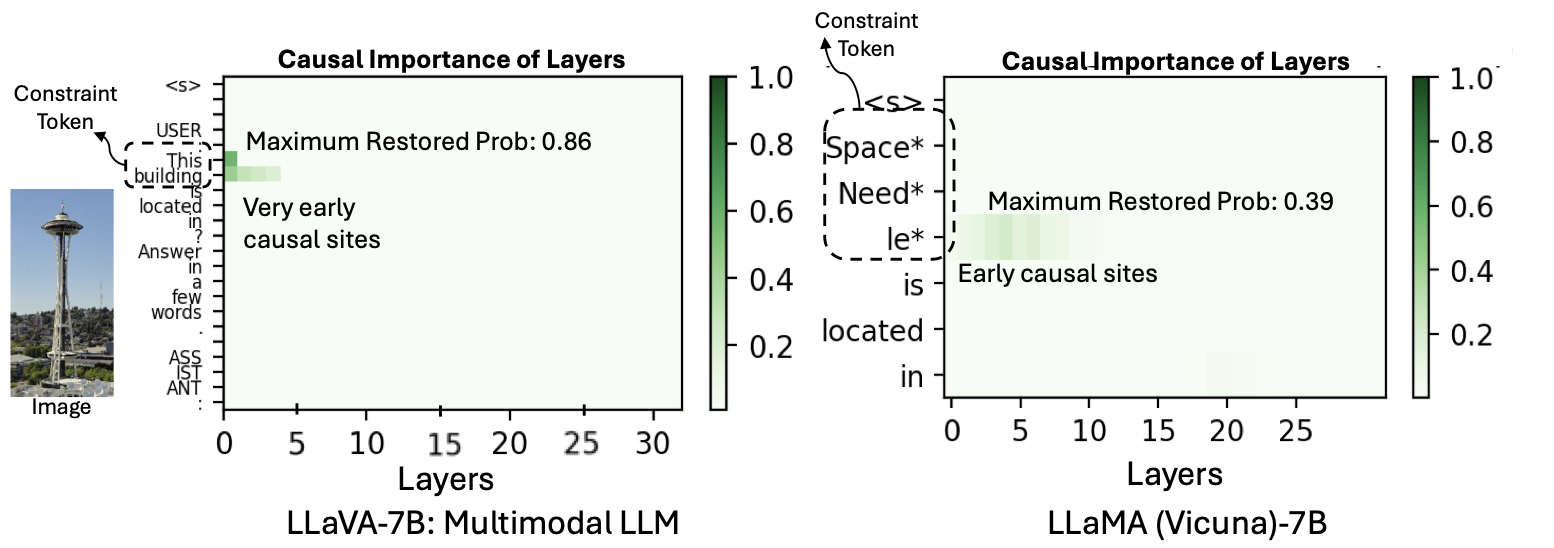
To answer the first question, we introduce MultimodalCausalTrace, which when combined with VQA-Constraints identifies the causal layers for the VQA task. Surprisingly, we find that very early MLP layers are causal for this task. However, when a similar query is given without visual prompt, the language model retrieves information from slightly later layers. This result shows that under the presence of a visual prompt, the language model retrieves information from its internal states differently.
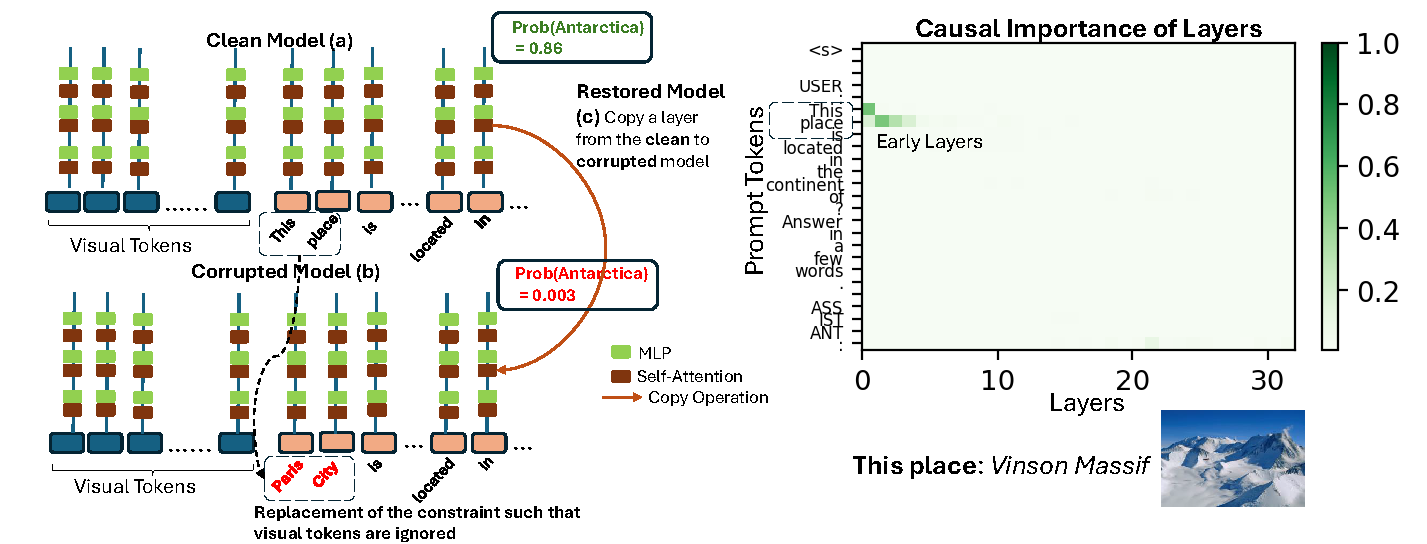
Below we show the difference between the causal layers of a MLLM and a language model.
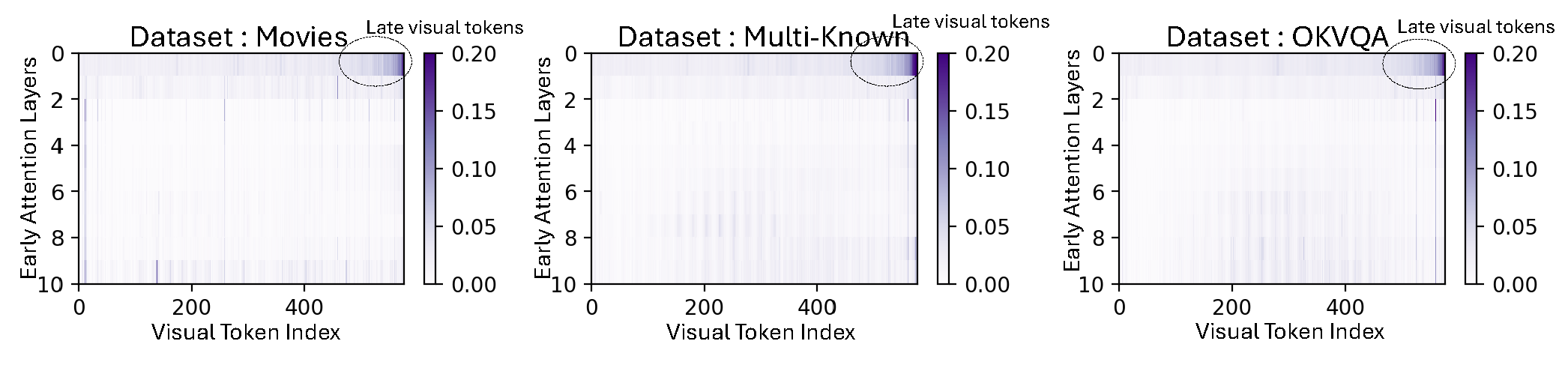
We then track the attention contributions from the visual tokens to the token positions corresponding to the causal layers. We find that only a subset of visual tokens (after the project layer) have a higher attention contributions. This potentially shows that a large amount of information is summarized by the projection layer. However, more investigation on this is needed to understand this transfer phenomenon.
Finally, we design a new and efficient model editing algorithm - MultEdit, which can edit the early MLP layers to incorporate rare knowledge into the MLLM. Although our objective is similar in essence to ROME, we note one main distinction: Using ROME in the multimodal setup will require access to a Multimodal Wikipedia Matrix, however our method circumvents this. Empirical results with our editing algorithm shows that the model edits incorporated by MultEdit have high efficacy and does not harm the prior knowledge of the model majorly, when compared with other baselines. Checkout our paper for model editing results!
📚 Paper: “Understanding Knowledge Storage and Transfer in Multimodal Language Models” NeurIPS 2024
Future Directions
This work opens up a plethora of open questions.
- Are there distinct circuits for different vision language tasks, and if so how do they differ?
- Can we perform batch-sequential model editing for MLLMs?
- What does the projection layer exactly do? We believe answering these questions will be critical towards understanding MLLMs in more depth and further desigining strategies to make them more reliable!
Conclusion
Through our works, we have uncovered various insightful findings about the inner workings of vision-language (or vision) models including diffusion models, vision transformers and multimodal language models. We have strategically used these insights towards developing light-weight applications which can potentially be used as practical solutions when efficiency is the need of the hour. As deep learning models seep into the production pipelines, we believe that the design of light-weight methods from model understanding insights will be critical towards making models more reliable.
Blog Authors: Keivan Rezaei, Samyadeep Basu, Sriram Balasubramanian, and Arman Zarei.